
Unveiling the Revolutionary Architecture behind LLMs - "Attention is all you need"
Paper that changed the trajectory of language AI forever

👋 Hi, this is Sagar with this week’s edition of the Mindful Matrix newsletter. Today, I’m going to discuss the foundational concepts originating from the famous paper "Attention Is All You Need", which has inspired the development of today's cutting-edge Large Language Models (LLMs), including ChatGPT. This edition extends beyond the usual length of my other editions.
If you find the post helpful, please share it with your friends and coworkers who are interested in learning about the underlying architecture and key concepts behind today’s state-of-the-art LLMs. Enjoy!
The world of language AI has undergone a revolutionary transformation with the advent of models like ChatGPT. Central to this revolution is the Transformer model, a term represented by the "T" in GPT, signifying its foundational role in the development of Large Language Models (LLMs). 7 years after its introduction, Transformer remains the backbone of modern Natural Language Processing(NLP).
The Genesis of Transformers
The journey of Transformers began in 2017 when Google researchers unveiled a groundbreaking paper titled "Attention Is All You Need". This paper introduced the Transformer architecture, which led to the Large Language Model (LLMs) revolution that we witness today. At the heart of this architecture lies the attention mechanism.
Before Transformers: The Evolution of Language Models
In the simplest term, language models function as probability distributions over sequences of words, learning these probabilities from a vast corpus of text. The core idea of language modelling is to understand the structure and patterns within language. By modeling the relationships between words (tokens) in a sentence, we can capture the context and meaning of the text.
Prior to the Transformer, nearly all language models used recurrent neural networks (RNNs). RNNs process a sentence word-by-word in order. They have short-term memory about what they've just seen and struggle to link concepts that are far apart. That's why tasks like generating a story or article were very difficult for them. This approach had a core constraint: its sequential nature and short-term memory.
The Transformer Architecture and Self-Attention
In NLP, words are represented as vectors(a sequence of numbers) to encode meaning, where similar words have closely related vectors, encapsulating both simple and complex ideas. If we just have a vector for each word it will be insufficient. For ex. does the word "bank" mean the edge of a river or a place to store money? Is it a noun or a verb? In order to figure out the correct vector for a particular instance of this word, we need to take into account its context.
A natural idea might be to look at the words next to it. This works okay, but it's not the best. In the sentence "I needed some money so I got in my car and took a drive down to the bank", the word that really tells me the most about "bank" is "money", even though its far away in the sentence. What I really want is to find informative words based on their meaning. This is what Transformers and attention are for.
The Transformer model revolutionizes sequence processing through its non-sequential architecture, leveraging self-attention to analyze and understand the relationships between words in a sentence simultaneously. This relationship is not just about the semantic similarity of words, but also about their grammatical and contextual relationships in the given sentence.

High level components of Transformer:
1. Input Embedding and Positional Encoding : The input text is tokenized into a sequence of words or subword units. Each token is converted into a numerical embedding vector. Embedding is a meaningful representation of each token (roughly a word) using a bunch of numbers. This embedding is what we provide as an input to our language models. Positional encoding is added to the embeddings to incorporate the order of tokens in the sequence (More on this Positional encoding later).
2. Encoder: The encoder consists of multiple identical layers, each containing a multi-headed self-attention mechanism and a feed-forward neural network. The self-attention mechanism allows each token to attend to other tokens in the input sequence, capturing dependencies and relationships between different parts of the text. The output of the encoder is a sequence of vectors representing the encoded input text. Note that the embedding only happens in the bottom-most encoder. Bottom most encoder would receive word embeddings, but in other encoders, it would be the output of the encoder that’s directly below.
3. Decoder: The decoding component is a stack of decoders similar to encoder. The decoder generates the summary one token at a time, attending to both the previously generated summary tokens (self-attention) and the encoded input text (encoder-decoder attention) to produce the next token in the summary.
Why positional encoding?
Consider the following input sentence - “Why Transformers are better than RNNs “and if we just exchange the position of two words (Transformers & RNNs) then the whole meaning of the sentence can be changed but for the model both sentences are equal because the order of words doesn't matter to it. So in order to preserve sequential information, researchers used a clever trick called positional encoding by adding position vector into embedding vector which holds the information about the position of each word. The researchers used sine and cosine waves for every even and odd position of the vector and this is how the Transformer retains the information about the order of words in a sentence without doing any sequential operations like RNN.


So why does this Transformer work exactly?
The key innovation of the Transformer model is the use of self-attention and multi-headed attention concept.

From encoder’s input vectors (in this case, the embedding of each word) we compute three things - a query, a key and a value. These vectors are created by multiplying the embedding by three matrices that we trained (WiQ ,WiK ,WiV) during the training process. These “query”, “key”, and “value” vectors can be think as an abstractions for now that are useful for calculating and thinking about attention.
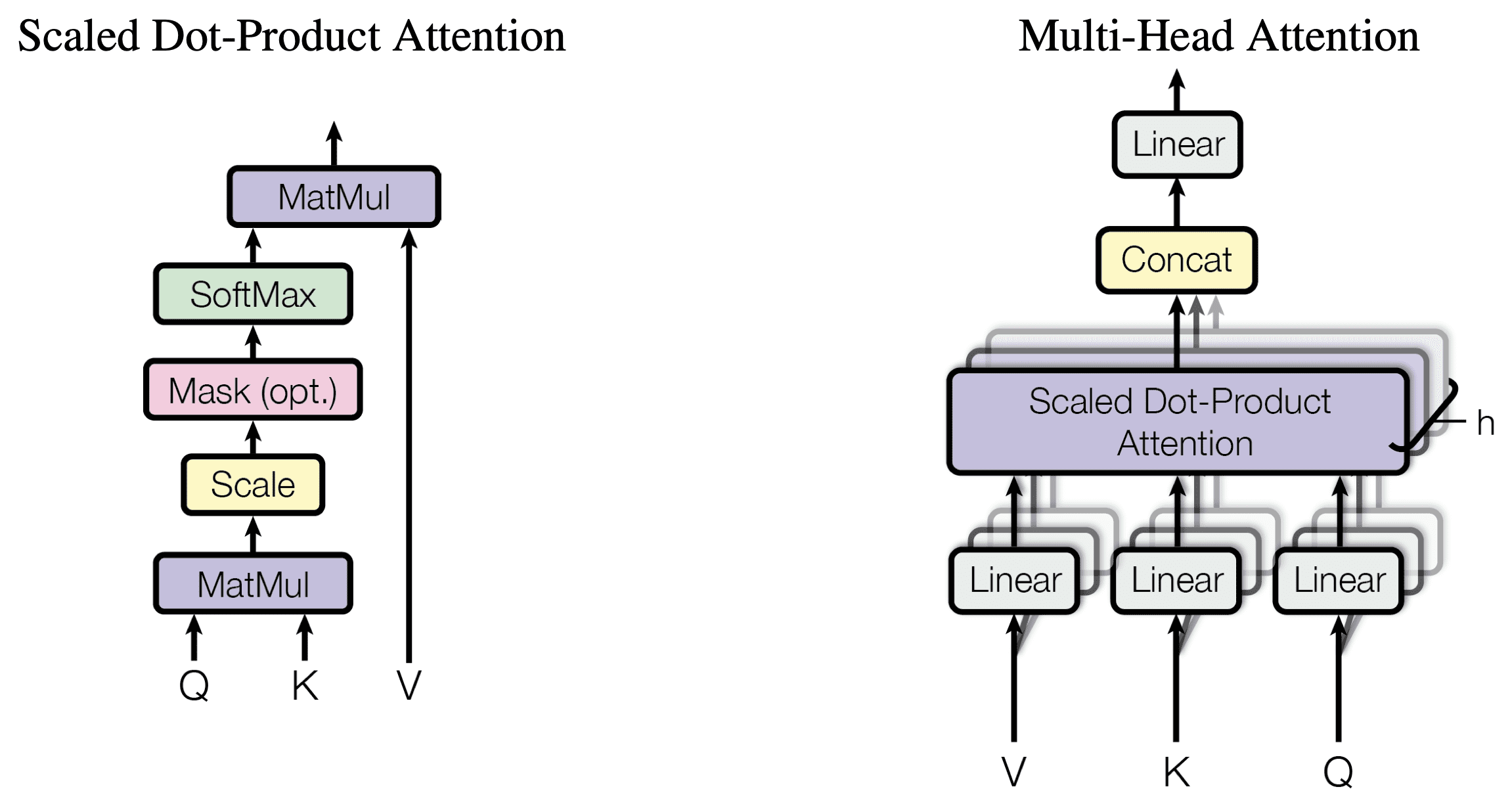
Scaled Dot Product
Let's further zoom in and see how it's building correlation. First, it will take the dot product between query and key which will output a correlation matrix where the values of each row in each column represent how much that word in the row related to the word in the column. And this matrix is also called the attention filter.
Then divided the values in the matrix by the square root of the number of dimensions(paper mentioned 6 in the experiment). Then a softmax layer is applied in order to convert these values into probabilities. Now we have an attention filter that exactly represents how much a word is related to every other word in the sentence.
Multi-headed attention
“Multi-headed” attention allows the model to jointly attend to different positions and learn multiple representations of the input sequence simultaneously. By performing multiple sets of attention computations in parallel, multi-head attention captures diverse aspects of the input sequence and enhances the model’s ability to capture complex and long range dependencies, and make the Transformer well-suited for tasks like text summarization. Each attention head has different query, key and value matrices.
If we do the same self-attention calculation we outlined above, just eight different times with different weight matrices, we end up with eight different Z matrices.
This leaves us with a bit of a challenge. The feed-forward layer is not expecting eight matrices – it’s expecting a single matrix (a vector for each word). So we need a way to condense these eight down into a single matrix.
How do we do that? We concat the matrices then multiply them by an additional weights matrix WO.

Output from multi-headed attention layer will get into an add and norm layer which takes the input from the attention layer and the previous input and then perform addition and normalization. And that's how the residual connections are also used in the network. Then the output will flow through a normal feed-forward network with add and norm layer to output the final encoded query and key (refer tranformer architecture dia at the top for the flow)
Decoder layer
The decoder in the Transformer begins with the same embedding and positional encoding as the encoder, initiated by a special token. It uses these inputs for multi-head attention, employing queries, keys, and values to integrate and normalize data. Subsequent layers use encoder outputs for queries and keys, aligning the generated output with the input sequence.
The self attention layers in the decoder operate in a slightly different way than the one in the encoder. In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence. This is done by masking future positions (setting them to -inf) before the softmax step in the self-attention calculation.
The multiheaded layer in decoded works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack.
The final decoder output is processed through a linear and softmax layer to predict the next word based on probability. The Linear layer is a simple fully connected neural network that projects the vector produced by the stack of decoders, into a much, much larger vector called a logits vector. The softmax layer then turns those scores into probabilities.
Now that we’ve covered the entire forward-pass process through a trained Transformer, it would be useful to glance at the intuition of training the model.
Training
During the training of a feed-forward neural network for word predictions, data flows in a specific direction. Initially, the network utilizes randomized QKV matrices, leading to inaccurate predictions. Training involves a process known as "back-propagation," where the difference between the predicted and actual next words is measured and used to adjust the QKV matrices across all layers. This iterative adjustment process refines the model's predictions! But note that this explanation overly simplifies the complex nature of the training process.
Closing Remarks
Understanding Transformers and self-attention is crucial in the AI era because they are the engines behind groundbreaking applications like ChatGPT. The Transformer’s attention mechanism enables it to model long-range dependencies, handle variable-length inputs, and achieve state-of-the-art performance in various natural language processing tasks. Their ability to process and learn from data in nuanced ways has revolutionized how machines understand human language and interact with us, making AI systems more efficient and intelligent.
References
https://arxiv.org/pdf/1706.03762.pdf
https://jalammar.github.io/illustrated-transformer/
Interesting reads you don’t want to miss
If you found this useful, please share it with your network and consider subscribing for more such insights.
If you haven’t subscribed, or followed me on LinkedIn, I’d love to connect with you. Please share your thoughts, feedback, and ideas, or even just to say hello!
Thanks for the shoutout Sagar!